Working Effectively with Legacy Code by Michael Feathers – Book Review:
Introduction
“Working Effectively with Legacy Code” by Michael Feathers is a book that addresses the challenges of working with large, complex, and poorly designed codebases. The book aims to provide practical guidance and techniques for software developers who must maintain, refactor, or extend existing code.
The book is divided into three parts. The first part introduces the concept of legacy code and explains why it is difficult to work with. It defines legacy code as code that lacks unit tests, is hard to change, and often contains subtle bugs. The author explains how legacy code can be a result of various factors such as outdated technologies, poor architecture, and lack of design.
The second part of the book describes techniques for working with legacy code. It introduces the concept of “characterization tests” that can help developers to understand the behavior of the codebase. The author then discusses techniques such as “seam identification”, “dependency breaking”, and “test-driving changes” that can help to refactor and improve legacy code without breaking its existing behavior.
The third part of the book discusses strategies for working with legacy code in a team setting. It provides guidance on how to deal with issues such as team resistance, code ownership, and change management. The author emphasizes the importance of communication and collaboration among team members to effectively work with legacy code.
Throughout the book, the author provides many real-world examples and code snippets to illustrate the techniques and concepts presented. The book also includes a comprehensive set of “code smells” and “dependency-breaking techniques” that can help developers to identify and address issues in legacy code.
Overall, “Working Effectively with Legacy Code” is a valuable resource for software developers who must work with legacy codebases. It provides practical techniques and strategies for dealing with the challenges of working with legacy code and can help developers to improve the quality and maintainability of existing code.
Part 1
Part one of “Working Effectively with Legacy Code” sets the stage for the rest of the book by defining what legacy code is, why it is difficult to work with, and what makes it valuable.
The author begins by defining legacy code as any code that lacks automated tests, which makes it difficult to refactor or extend safely. He explains that legacy code often accumulates over time due to changing requirements, evolving technologies, and shifting priorities, and may not have been designed with maintainability or testability in mind.
The author then discusses why working with legacy code is difficult. He identifies several characteristics of legacy code that make it challenging, including its size and complexity, its lack of structure and modularity, and its tight coupling and interdependence. He explains that legacy code often contains “code smells” such as long methods, global variables, and deep inheritance hierarchies, which make it difficult to understand and change.
Despite its challenges, the author argues that legacy code is valuable and worth investing in. He explains that legacy code represents a significant investment of time and resources, and often contains valuable business logic and domain knowledge. He suggests that developers should approach legacy code as an opportunity to learn and improve their skills, rather than simply as a burden to be borne.
Part one of the book concludes by introducing the concept of “characterization tests”, which are a form of automated tests that can help developers to understand the behavior of legacy code. The author argues that characterization tests are a crucial first step in working with legacy code, as they provide a safety net for making changes and refactoring the codebase. He suggests that developers should focus on creating characterization tests before attempting to refactor or extend legacy code, as this will help them to gain a better understanding of the codebase and reduce the risk of introducing bugs.
Here are some examples from Part One of “Working Effectively with Legacy Code”:
- Legacy Code Example:
- In Chapter 1, the author provides an example of a legacy codebase that has grown over time without a clear design or architecture. He notes that the codebase contains many interdependent modules and global variables, which make it difficult to understand and change. For example, imagine a legacy codebase for a financial application that has been in use for several years. The codebase contains multiple modules that are tightly coupled, and many global variables are used to pass information between modules. This makes it difficult to understand the behavior of the application and make changes safely.
- Code Smell Example:
- In Chapter 2, the author provides an example of a code smell – long methods – that is common in legacy code. He notes that long methods make it difficult to understand the behavior of the code and make changes safely. For example, imagine a legacy codebase that contains a method for processing customer orders that is over 500 lines long. This method contains many nested if statements and loops, making it difficult to understand the behavior of the code and make changes safely.
- Characterization Test Example:
- In Chapter 3, the author provides an example of a characterization test for a legacy codebase. He notes that characterization tests are a form of automated tests that are not concerned with the correctness of the code, but rather with its behavior. For example, imagine a legacy codebase for a web application that contains a complex search algorithm. A characterization test for this algorithm might simulate user input and verify that the output is as expected, without worrying about the implementation details.
- Seam Example:
- In Chapter 4, the author provides an example of a seam – a place in the code where behavior can be changed without affecting the rest of the codebase. He notes that seams can be used to make changes to legacy code safely. For example, imagine a legacy codebase for a game that contains a method for calculating the score. The method takes a single argument – the current score – and returns the new score. A seam can be introduced by passing in a function that calculates the new score, allowing the behavior to be changed without affecting the rest of the codebase.
- Dependency-Breaking Technique Example:
- In Chapter 5, the author provides an example of a dependency-breaking technique – extracting interfaces – that can be used to make legacy code more modular and testable. He notes that dependencies between modules are a major source of complexity in legacy code and can make it difficult to understand and change. For example, imagine a legacy codebase for a video streaming application that contains a module for handling user authentication. By extracting an interface for the authentication module, other modules can use the interface instead of directly accessing the implementation, making it easier to change the behavior of the module and test it independently.
Part 2
Part Two of the book focuses on techniques for improving the safety and maintainability of legacy code. The author emphasizes that the key to working with legacy code is to be able to make changes safely and that this requires a combination of understanding the behavior of the code and having effective automated tests.
The chapters in Part Two cover a range of topics related to improving the safety and maintainability of legacy code. Here is an overview of some of the key concepts covered in each chapter:
- I Don’t Have Much Time and I Have to Change It:
- This chapter focuses on techniques for making changes to legacy code quickly and safely. The author emphasizes the importance of understanding the behavior of the code before making changes and provides examples of techniques for making changes safely, such as using temporary variables to isolate code changes and using a debugger to understand the behavior of the code.
- Example: A legacy codebase has a function that takes a long time to execute due to inefficient algorithms. The developer needs to make changes to improve the performance but also needs to ensure that the behavior of the function remains the same. To do this safely, the developer can use a profiler to identify the slowest parts of the function and make changes to those areas, using temporary variables to isolate the changes and a debugger to test the behavior.
- This chapter focuses on techniques for making changes to legacy code quickly and safely. The author emphasizes the importance of understanding the behavior of the code before making changes and provides examples of techniques for making changes safely, such as using temporary variables to isolate code changes and using a debugger to understand the behavior of the code.
- It Takes Forever to Make a Change:
- This chapter focuses on techniques for reducing the time it takes to make changes to legacy code. The author emphasizes the importance of understanding the dependencies between modules and minimizing them where possible. He also provides examples of techniques for making changes safely, such as using conditional compilation and extracting methods.
- Example: A legacy codebase has a complex set of interdependent modules, making it difficult to make changes without affecting other parts of the system. To reduce the time it takes to make changes, the developer can use techniques such as refactoring to reduce the complexity of the code and identify the dependencies between modules to minimize them where possible. They can also use techniques such as conditional compilation to isolate changes and extract methods to make the code more modular.
- This chapter focuses on techniques for reducing the time it takes to make changes to legacy code. The author emphasizes the importance of understanding the dependencies between modules and minimizing them where possible. He also provides examples of techniques for making changes safely, such as using conditional compilation and extracting methods.
- How Do I Add a Feature?:
- This chapter focuses on techniques for adding new features to legacy code. The author emphasizes the importance of understanding the existing behavior of the code and identifying the seams where new behavior can be added safely. He also provides examples of techniques for adding new features safely, such as using a characterization test to understand the behavior of the code and introducing a new module to handle the new feature.
- Example: A legacy codebase does not have the ability to handle a new type of input data. The developer needs to add support for this new data type but needs to ensure that the existing behavior of the system remains unchanged. To add this feature safely, the developer can use techniques such as a characterization test to understand the existing behavior of the code, identify the seams where new behavior can be added safely, and introduce a new module to handle the new feature.
- This chapter focuses on techniques for adding new features to legacy code. The author emphasizes the importance of understanding the existing behavior of the code and identifying the seams where new behavior can be added safely. He also provides examples of techniques for adding new features safely, such as using a characterization test to understand the behavior of the code and introducing a new module to handle the new feature.
- I Can’t Get This Class into a Test Harness:
- This chapter focuses on techniques for testing legacy code that was not designed with testing in mind. The author emphasizes the importance of identifying the seams where behavior can be changed and using them to introduce testability into the code. He also provides examples of techniques for testing legacy code, such as using a driver module to simulate input and output and introducing a test-specific subclass to override behavior.
- Example: A legacy codebase has a class that was not designed with testing in mind, making it difficult to write automated tests for it. To make this class testable, the developer can identify the seams where the behavior of the class can be changed, such as methods that take input parameters or return values, and use those seams to introduce testability. They can also use techniques such as a driver module to simulate input and output and introduce a test-specific subclass to override behavior.
- This chapter focuses on techniques for testing legacy code that was not designed with testing in mind. The author emphasizes the importance of identifying the seams where behavior can be changed and using them to introduce testability into the code. He also provides examples of techniques for testing legacy code, such as using a driver module to simulate input and output and introducing a test-specific subclass to override behavior.
- I’m Changing the Same Code All Over the Place:
- This chapter focuses on techniques for reducing the amount of duplicate code in a legacy codebase. The author emphasizes the importance of identifying the common behavior that is duplicated and extracting it into a single module or method. He also provides examples of techniques for reducing duplicate code, such as using a template method pattern to encapsulate common behavior and using a superclass to encapsulate common behavior across multiple subclasses.
- Example: A legacy codebase has a lot of duplicate code, making it difficult to maintain and change. To reduce the amount of duplicate code, the developer can identify the common behavior that is duplicated and extract it into a single module or method. They can also use techniques such as a template method pattern to encapsulate common behavior and a superclass to encapsulate common behavior across multiple subclasses.
- This chapter focuses on techniques for reducing the amount of duplicate code in a legacy codebase. The author emphasizes the importance of identifying the common behavior that is duplicated and extracting it into a single module or method. He also provides examples of techniques for reducing duplicate code, such as using a template method pattern to encapsulate common behavior and using a superclass to encapsulate common behavior across multiple subclasses.
These examples demonstrate how the techniques outlined in Part Two of the book can be applied to real-world scenarios in legacy codebases. By using these techniques, developers can make changes to legacy code safely and with confidence, improving the maintainability and sustainability of the codebase over time.
Part 3
Part Three of the book focuses on specific techniques and tools that can be used to work effectively with legacy code. Each chapter provides an overview of a particular technique or tool, along with examples of how it can be used to improve the quality and maintainability of legacy code.
- The Seam Model:
- This chapter introduces the Seam Model, which is a way to identify and introduce seams into legacy code that can be used to change the behavior of the code safely. Seams are places in the code where behavior can be changed without affecting the rest of the system and can include methods that take input parameters or return values, global variables, and system calls.
- In the Seam Model chapter, the author provides an example of a legacy codebase that sends email notifications and shows how to introduce a seam in the code to change the behavior of the email-sending function. The seam is introduced by modifying the function to take a parameter that specifies the email-sending method to use and then calling the function with different parameters depending on the desired behavior.
- Tools:
- This chapter discusses a variety of tools that can be used to work effectively with legacy code, including refactoring tools, automated testing tools, profiling tools, and build tools. These tools can help developers to automate repetitive tasks, identify areas of the code that need improvement, and improve the overall quality of the codebase.
- The Tools chapter provides examples of various tools that can be used to work effectively with legacy code. For example, the author discusses how to use refactoring tools to extract code into smaller, more manageable pieces, and how to use automated testing tools to ensure that changes to the codebase do not introduce regressions. The chapter also provides guidance on how to choose the right tools for a particular project, and how to integrate tools into an existing development workflow.
- Cross-Cutting Concerns:
- This chapter focuses on cross-cutting concerns, which are aspects of a system that affect multiple parts of the codebase. Examples of cross-cutting concerns include logging, error handling, and security. To address cross-cutting concerns in legacy code, the chapter recommends using techniques such as aspect-oriented programming and dependency injection.
- In the Cross-Cutting Concerns chapter, the author provides an example of a legacy codebase that lacks proper error handling and shows how to introduce error handling using aspect-oriented programming (AOP). AOP allows developers to separate cross-cutting concerns such as error handling from the core logic of the code, making it easier to maintain and modify the codebase over time.
- Putting It All Together:
- This chapter provides an overview of how to use the techniques and tools discussed in the previous chapters to work effectively with legacy code. The chapter outlines a process for working with legacy code that includes identifying the parts of the code that need improvement, introducing seams to make changes safely, and using tools to automate repetitive tasks and improve code quality.
- The Putting It All Together chapter provides an example of a legacy codebase that is difficult to modify due to tight coupling between modules. The chapter shows how to use the techniques and tools discussed in earlier chapters to identify the areas of the codebase that need improvement, introduce seams to safely modify the code, and refactor the code to reduce complexity and improve maintainability.
- My Application Has No Structure:
- This chapter discusses the challenges of working with legacy code that lacks structure or architecture and provides recommendations for introducing structure into such code. Techniques discussed include using a layered architecture, introducing design patterns such as the factory pattern and the template method pattern, and using refactoring to extract modules and reduce complexity.
- The My Application Has No Structure chapter provides an example of a legacy codebase that lacks a clear architecture or structure, making it difficult to understand and modify. The chapter shows how to introduce a layered architecture to the codebase, and provides guidance on how to use design patterns such as the factory pattern and the template method pattern to reduce coupling and improve maintainability.
Overall, Part Three of “Working Effectively with Legacy Code” provides a wealth of practical advice and examples on how to work effectively with legacy code. The techniques and tools discussed in this part of the book can be applied to a wide range of legacy codebases and can help developers to improve the quality, maintainability, and agility of their software systems.
Final words:
The final words of “Working Effectively with Legacy Code” encourage readers to embrace the challenges and rewards of working with legacy code, and to use the techniques and tools presented in the book to make positive changes in their codebases. The author emphasizes that although working with legacy code can be difficult and frustrating at times, it is also an opportunity to learn and grow as a developer, and to make a real difference in the quality and maintainability of software systems.
The book concludes with the following words: “Working with legacy code can be tough, but it’s also an opportunity to make a real difference. Use the techniques and tools presented in this book to take control of your codebase, and to make it a source of pride and satisfaction. With patience, persistence, and a willingness to learn, you can transform even the most challenging legacy code into a well-designed, maintainable, and responsive software system.”
Comparing modern C++ and Rust in terms of safety and performance
C++ and Rust are two popular programming languages that offer a balance between performance and safety. While C++ has been around for decades and is widely used in many applications, Rust is a relatively new language that has gained popularity for its safety features. In this post, we will compare the safety and performance of modern C++ and Rust.
Safety
Null Pointers:
One of the most common errors in C++ is null pointer dereferencing. A null pointer is a pointer that does not point to a valid memory location. Dereferencing a null pointer can result in a segmentation fault, which can crash the program. In C++, it is the responsibility of the programmer to ensure that pointers are not null before dereferencing them.
Rust, on the other hand, has a built-in option type that ensures that a value is either present or absent. This eliminates the need for null pointers. For example, consider the following C++ code:
int* ptr = nullptr;
*ptr = 42;
This code will crash with a segmentation fault, because the pointer ptr is null. In Rust, we would write this code as follows:
let mut opt = None;
opt = Some(42);In this case, opt is an option type that is either Some with a value or None. If we try to access opt when it is None, Rust will throw a runtime error. This eliminates the possibility of null pointer dereferencing.
Data Races:
Another common error in concurrent programming is data races. A data race occurs when two or more threads access the same memory location simultaneously, and at least one of the accesses is a write. This can result in undefined behavior, including incorrect results or crashes.
C++ has a number of synchronization primitives that can be used to prevent data races, such as mutexes and condition variables. However, it is the responsibility of the programmer to ensure that these primitives are used correctly. In Rust, the ownership and borrowing system ensures that only one thread can modify a value at a time, preventing data races. For example, consider the following C++ code:
#include <thread>
#include <iostream>
int x = 0;
void increment()
{
for (int i = 0; i < 1000000; i++)
{ x++; }
}
int main()
{
std::thread t1(increment);
std::thread t2(increment);
t1.join();
t2.join();
std::cout << x << std::endl;
}In this code, we have two threads that increment the variable x simultaneously. This can result in a data race, because both threads are modifying the same memory location. In Rust, we can use the ownership and borrowing system to prevent this kind of error:
use std::sync::Mutex;
let x = Mutex::new(0);
let t1 = std::thread::spawn(|| {
for _ in 0..1000000 {
let mut x = x.lock().unwrap();
*x += 1;
}
});
let t2 = std::thread::spawn(|| {
for _ in 0..1000000 {
let mut x = x.lock().unwrap();
*x += 1;
}
});
t1.join().unwrap();
t2.join().unwrap();
println!("{}", *x.lock().unwrap());
In this code, we use a mutex to ensure that only one thread can modify x at a time. This prevents data races and ensures that the output is correct.
Performance:
Compilation Time: One area where C++ has traditionally been faster than Rust is in compilation time. C++ compilers have been optimized for decades to compile large code bases quickly. However, Rust has been improving its compilation times with recent releases.
For example, consider compiling the following C++ code:
#include <iostream>
int main() {
std::cout << "Hello, world!" << std::endl;
return 0;
}
Using the Clang compiler on a MacBook Pro with a 2.6 GHz Intel Core i7 processor, this code takes about 0.5 seconds to compile. In comparison, compiling the equivalent Rust code:
fn main() {
println!("Hello, world!");
}
Using the Rust compiler takes about 0.8 seconds. While C++ is faster in this example, Rust is improving its compilation times and is expected to become more competitive in the future.
Execution Time:
When it comes to execution time, C++ and Rust are both high-performance languages that can be used to write fast, low-level code. However, the specific performance characteristics of each language can vary depending on the task at hand.
For example, consider the following C++ code that calculates the sum of all integers from 1 to 1 billion:
#include <iostream>
int main() {
long long sum = 0;
for (int i = 1; i <= 1000000000; i++) {
sum += i;
}
std::cout << sum << std::endl;
return 0;
}
Using the Clang compiler on a MacBook Pro with a 2.6 GHz Intel Core i7 processor, this code takes about 5 seconds to execute. In comparison, the equivalent Rust code:
fn main() {
let mut sum = 0;
for i in 1..=1000000000 {
sum += i;
}
println!("{}", sum);
}
Using the Rust compiler takes about 6 seconds to execute on the same machine. In this case, C++ is slightly faster than Rust, but the difference is not significant.
Memory Usage:
Another important factor to consider when comparing performance is memory usage. C++ and Rust both provide low-level control over memory, which can be beneficial for performance. However, this also means that the programmer is responsible for managing memory and avoiding memory leaks.
For example, consider the following C++ code that creates a large array of integers:
#include <iostream>
#include <vector>
int main() {
std::vector<int> arr(100000000);
std::cout << arr.size() << std::endl;
return 0;
}
This code creates a vector of 100 million integers, which takes up about 400 MB of memory. In comparison, the equivalent Rust code:
fn main() {
let arr = vec![0; 100000000];
println!("{}", arr.len());
}
Using the Rust compiler takes up about 400 MB of memory. In this case, C++ and Rust have similar memory usage.
Conclusion
Both C++ and Rust offer a balance between performance and safety, but Rust’s ownership and borrowing system gives it an edge in terms of safety. Rust’s memory safety features make it less prone to common programming errors like null pointer dereferencing, data races, and memory leaks.
In terms of performance, both C++ and Rust are high-performance languages, but Rust’s memory safety features and zero-cost abstractions give it an advantage over C++. Rust’s efficient concurrency also makes it well-suited for high-performance and parallel computing.
Ultimately, the choice between C++ and Rust depends on the specific needs of your project. If you need low-level memory management and direct hardware access, C++ may be the better choice. If you prioritize safety and memory efficiency, Rust may be the way to go.
The 10 Most Common Mistakes That WordPress Developers Make
We are only human, and one of the traits of being a human is that we make mistakes. On the other hand, we are also self-correcting, meaning we tend to learn from our mistakes and hopefully are thereby able to avoid making the same ones twice. A lot of the mistakes I have made in the WordPress realm originate from trying to save time when implementing solutions. However, these would typically rear their heads down the road when issues would crop up as a result of this approach. Making mistakes is inevitable. However, learning from other people’s oversights (and your own of course!) is a road you should proactively take.
Engineers look like superheroes, but we’re still human. Learn from us.
Common Mistake #1: Keeping the Debugging Off
Why should I use debugging when my code is working fine? Debugging is a feature built into WordPress that will cause all PHP errors, warnings, and notices (about deprecated functions, etc.) to be displayed. When debugging is turned off, there may be important warnings or notices being generated that we never see, but which might cause issues later if we don’t deal with them in time. We want our code to play nicely with all the other elements of our site. So, when adding any new custom code to WordPress, you should always do your development work with debugging turned on (but make sure to turn it off before deploying the site to production!).
To enable this feature, you’ll need to edit the wp-config.php file in the root directory of your WordPress install. Here is a snippet of a typical file:
// Enable debuggingdefine('WP_DEBUG', true);
// Log all errors to a text file located at
/wp-content/debug.logdefine('WP_DEBUG_LOG', true);
// Don’t display error messages write them to the log file
/wp-content/debug.logdefine('WP_DEBUG_DISPLAY', false);
// Ensure all PHP errors are written to the log file and not displayed on screen@ini_set('display_errors', 0);
This is not an exhaustive list of configuration options that can be used, but this suggested setup should be sufficient for most debugging needs.
Common Mistake #2: Adding Scripts and Styles Using wp_head Hook
What is wrong with adding the scripts into my header template? WordPress already includes a plethora of popular scripts. Still, many developers will add additional scripts using the wp_head hook. This can result in the same script, but a different version, being loaded multiple times.
Enqueuing here comes to the rescue, which is the WordPress friendly way of adding scripts and styles to our website. We use enqueuing to prevent plugin conflicts and handle any dependencies a script might have. This is achieved by using the inbuilt functions wp_enqueue_script or wp_enqueue_style to enqueue scripts and styles respectively. The main difference between the two functions is that with wp_enqueue_script we have an additional parameter that allows us to move the script into the footer of the page.
wp_register_script( $handle, $src, $deps = array(), $ver = false, $in_footer = false )wp_enqueue_script( $handle, $src = false, $deps = array(), $ver = false, $in_footer = false )&nbsp;wp_register_style( $handle, $src, $deps = array(), $ver = false, $media = 'all' )wp_enqueue_style( $handle, $src = false, $deps = array(), $ver = false, $media = 'all' )
If the script is not required to render content above the fold, we can safely move it to the footer to make sure the content above the fold loads quickly. It’s good practice to register the script first before enqueuing it, as this allows others to deregister your script via the handle in their own plugins, without modifying the core code of your plugin. In addition to this, if the handle of a registered script is listed in the array of dependencies of another script that has been enqueued, that script will automatically be loaded prior to loading that highlighted enqueued script.
Common Mistake #3: Avoiding Child Themes and Modifying WordPress Core Files
Always create a child theme if you plan on modifying a theme. Some developers will make changes to the parent theme files only to discover after an upgrade to the theme that their changes have been overwritten and lost forever.
To create a child theme, place a style.css file in a subdirectory of the child theme’s folder, with the following content:
/* Theme Name: Twenty Sixteen Child Theme</p> URI: http://example.com/twenty-fifteen-child/</p> Description: Twenty Fifteen Child Theme</p> Author: John Doe Author URI: http://example.com</p> Template: twentysixteen</p> Version: 1.0.0</p> License: GNU General Public License v2 or later License</p> URI: http://www.gnu.org/licenses/gpl-2.0.html</p> Tags: light, dark, two-columns, right-sidebar, responsive-layout, accessibility-ready Text Domain: twenty-sixteen-child */
The above example creates a child theme based on the default WordPress theme, Twenty Sixteen. The most important line of this code is the one containing the word “Template” which must match the directory name of the parent theme you are cloning the child from.
The same principles apply to WordPress core files: Don’t take the easy route by modifying the core files. Put in that extra bit of effort by employing WordPress pluggable functions and filters to prevent your changes from being overwritten after a WordPress upgrade. Pluggable functions let you override some core functions, but this method is slowly being phased out and replaced with filters. Filters achieve the same end result and are inserted at the end of WordPress functions to allow their output to be modified. A trick is always to wrap your functions with if ( !function_exists() ) when using pluggable functions since multiple plugins trying to override the same pluggable function without this wrapper will produce a fatal error.
Common Mistake #4: Hardcoding Values
Often it looks quicker to just hardcode a value (such as a URL) somewhere in the code, but the time spent down the road debugging and rectifying issues that arise as a result of this is far greater. By using the corresponding function to generate the desired output dynamically, we greatly simplify subsequent maintenance and debugging of our code. For example, if you migrate your site from a test environment to production with hardcoded URLs, all of a sudden you’ll notice your site it is not working. This is why we should employ functions, like the one listed below, for generating file paths and links:
// Get child theme directory uristylesheet_directory_uri();
// Get parent theme directoryget_template_directory_uri();
// Retrieves url for the current site site_url();
Another bad example of hardcoding is when writing custom queries. For example, as a security measure, we change the default WordPress datatable prefix from wp_ to something a little more unique, like wp743_. Our queries will fail if we ever move the WordPress install, as the table prefixes can change between environments. To prevent this from happening, we can reference the table properties of the wpdb class:
global $wpdb;$user_count = $wpdb-&gt; get_var( "SELECT COUNT(*) FROM $wpdb-&gt;users" );
Notice how I am not using the value wp_users for the table name, but instead, I’m letting WordPress work it out. Using these properties for generating the table names will help ensure that we return the correct results.
Common Mistake #5: Not Stopping Your Site From Being Indexed
Why wouldn’t I want search engines to index my site? Indexing is good, right? Well, when building a website, you don’t want search engines to index your site until you have finished building it and have established a permalink structure. Furthermore, if you have a staging server where you test site upgrades, you don’t want search engines like Google indexing these duplicate pages. When there are multiple pieces of indistinguishable content, it is difficult for search engines to decide which version is more relevant to a search query. Search engines will in such cases penalize sites with duplicate content, and your site will suffer in search rankings as a result of this.
As shown below, WordPress Reading Settings has a checkbox that reads “Discourage search engines from indexing this site”, although this does have an important-to-note underneath stating that “It is up to search engines to honor this request”.
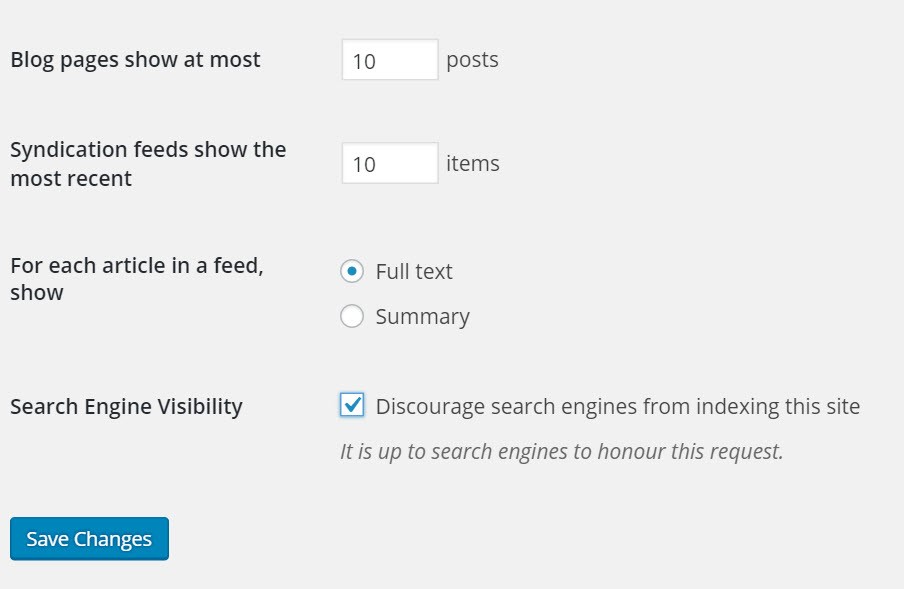
Bear in mind that search engines often do not honor this request. Therefore, if you want to reliably prevent search engines from indexing your site, edit your .htaccess file and insert the following line:
Header set X-Robots-Tag “noindex, nofollow”
Common Mistake #6: Not Checking if a Plugin is Active
Why should I check if a plugin function exists if my plugin is always switched on? For sure, 99% of the time your plugin will be active. However, what about that 1% of the time when for some reason it has been deactivated? If and when this occurs, your website will probably display some ugly PHP errors. To prevent this, we can check to see if the plugin is active before we call its functions. If the plugin function is being called via the front-end, we need to include the plugin.php library in order to call the function is_plugin_active():
include_once( ABSPATH . ‘wp-admin/includes/plugin.php’ );
if ( is_plugin_active( ‘plugin-folder/plugin-main-file.php’ ) ) {// Run plugin code}
This technique is usually quite reliable. However, there could be instances where the author has changed the main plugin directory name. A more robust method would be to check for the existence of a class in the plugin:
if( class_exists( ‘WooCommerce’ ) ) { // The plugin WooCommerce is turned on}
Authors are less likely to change the name of a plugin’s class, so I would generally recommend using this method.
Common Mistake #7: Loading Too Many Resources
Why should we be selective in loading plugin resources for pages? There is no valid reason to load styles and scripts for a plugin if that plugin is not used on the page that the user has navigated to. By only loading plugin files when necessary, we can reduce our page loading time, which will result in an improved end user experience. Take, for example, a WooCommerce site, where we only want the plugin to be loaded on our shopping pages. In such a case, we can selectively remove any files from being loaded on all the other sites pages to reduce bloating. We can add the following code to the theme or plugin’s functions.php file:
function load_woo_scripts_styles(){
if( function_exists( 'is_woocommerce' ) ){
// Only load styles/scripts on Woocommerce pages
if(! is_woocommerce() && ! is_cart() && ! is_checkout() ) {
// Dequeue scripts.
wp_dequeue_script('woocommerce');
wp_dequeue_script('wc-add-to-cart');
wp_dequeue_script('wc-cart-fragments');
// Dequeue styles.
wp_dequeue_style('woocommerce-general');
wp_dequeue_style('woocommerce-layout');
wp_dequeue_style('woocommerce-smallscreen');
}
}
}
Scripts can be removed with the function wp_dequeue_script($handle) via the handle with which they were registered. Similarly, wp_dequeue_style($handle) will prevent stylesheets from being loaded. However, if this is too challenging for you to implement, you can install the Plugin Organizer that provides the ability to load plugins selectively based on certain criteria, such as a post type or page name. It’s a good idea to disable any caching plugins, like W3Cache, that you may have switched on to stop you from having to refresh the cache constantly to reflect any changes you have made.
Common Mistake #8: Keeping the Admin Bar
Can’t I just leave the WordPress Admin Bar visible for everyone? Well, yes, you could allow your users access to the admin pages. However, these pages very often do not visually integrate with your chosen theme and don’t provide a seamless integration. If you want your site to look professional, you should disable the Admin Bar and provide a front-end account management page of your own:
add_action('after_setup_theme', 'remove_admin_bar');
function remove_admin_bar() {
if (!current_user_can('administrator') && !is_admin()) {
show_admin_bar(false);
}
}
The above code, when copied into your theme’s functions.php file will only display the Admin Bar for administrators of the site. You can add any of the WordPress user roles or capabilities into the current_user_can($capability) function to exclude users from seeing the admin bar.
Common Mistake #9: Not Utilizing the GetText Filter
I can use CSS or JavaScript to change the label of a button, what’s wrong with that? Well, yes, you can. However, you’re adding superfluous code and extra time to render the button, when you can instead use one of the handiest filters in WordPress, called gettext. In conjunction with a plugin’s textdomain, a unique identifier that ensures WordPress can distinguish between all loaded translations, we can employ the gettextfilter to modify the text before the page is rendered. If you search the source code for the function load_plugin_textdomain($domain), it will give you the domain name we need to override the text in question. Any reputable plugin will ensure that the textdomain for a plugin is set on initialization of the plugin. If it’s some text in a theme that you want to change, search for the load_theme_textdomain($domain) line of code. Using WooCommerce once again as an example, we can change the text that appears for the “Related Products” heading. Insert the following code into your theme’s functions.php file:
function translate_string( $translated_text, $untranslated_text, $domain ) {
if ( $translated_text == 'Related Products') {
$translated_text = __( 'Other Great Products', 'woocommerce' );
}
return $translated_text;
}
add_filter( 'gettext', 'translate_string', 15, 3 );
This filter hook is applied to the translated text by the internationalization functions __() and _e(), as long as the textdomain is set via the aforementioned functions.
_e( ‘Related Products’, ‘woocommerce’ );
Search your plugins for these internationalization functions to see what other strings you can customize.
Common Mistake #10: Keeping the Default Permalinks
By default, WordPress uses a query string with the post’s ID to return the specified content. However, this is not user-friendly and users may remove pertinent parts of the URL when copying it. More importantly, these default permalinks do not use a search engine friendly structure. Enabling what we call “pretty” permalinks will ensure our URLs contain relevant keywords from the post title to improve performance in search engine rankings. It can be quite a daunting task having to retrospectively modify your permalinks, especially if your site has been running for a significant period of time, and you’ve got hundreds of posts already indexed by search engines. So after you’ve installed WordPress, ensure you promptly change your permalinks structure to something a little more search engine friendly than just a post ID. I generally use the post name for the majority of sites I build, but you can customize the permalink to whatever format you like using the available permalink structure tags.
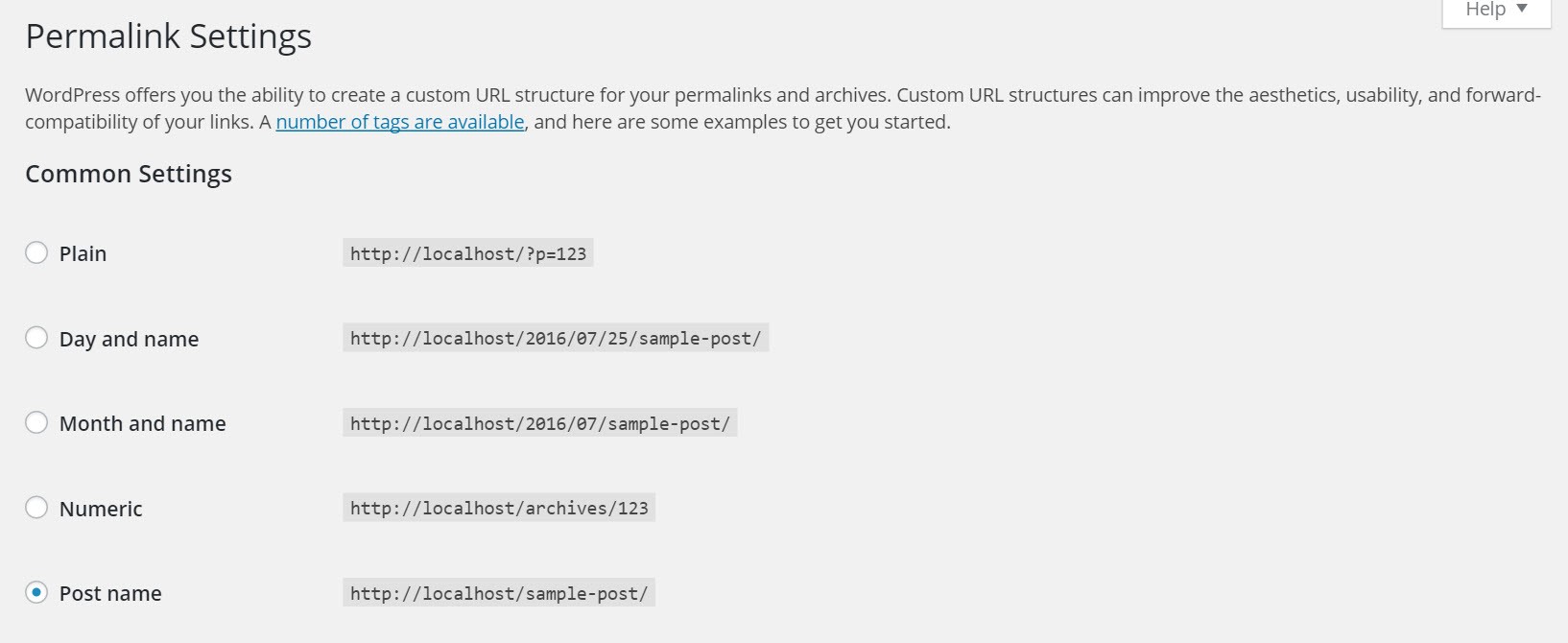
Conclusion
This article is by no means an exhaustive list of mistakes made by WordPress developers. If there’s one thing you should take away from this article, though, it’s that you should never take shortcuts (and that’s true in any development platform, not just in WordPress!). Time saved now by poor programming practices will come back to haunt you later. Feel free to share with us some mistakes that you have made in the past – and more importantly any lessons learned – by leaving a comment below.
This article is originally posted here.
Top 10 Most Common C++ Mistakes That Developers Make
There are many pitfalls that a C++ developer may encounter. This can make quality programming very hard and maintenance very expensive. Learning the language syntax and having good programming skil…
Source: Top 10 Most Common C++ Mistakes That Developers Make
After All These Years, the World is Still Powered by C Programming
Many of the C projects that exist today were started decades ago. The UNIX operating system’s development started in 1969, and its code was rewritten in C in 1972. The C language was actually creat…
Source: After All These Years, the World is Still Powered by C Programming
After All These Years, the World is Still Powered by C Programming
Many of the C projects that exist today were started decades ago.
The UNIX operating system’s development started in 1969, and its code was rewritten in C in 1972. The C language was actually created to move the UNIX kernel code from assembly to a higher level language, which would do the same tasks with fewer lines of code.
Oracle database development started in 1977, and its code was rewritten from assembly to C in 1983. It became one of the most popular databases in the world.
In 1985 Windows 1.0 was released. Although Windows source code is not publicly available, it’s been stated that its kernel is mostly written in C, with some parts in assembly. Linux kernel development started in 1991, and it is also written in C. The next year, it was released under the GNU license and was used as part of the GNU Operating System. The GNU operating system itself was started using C and Lisp programming languages, so many of its components are written in C.
But C programming isn’t limited to projects that started decades ago, when there weren’t as many programming languages as today. Many C projects are still started today; there are some good reasons for that.
How is the World Powered by C?
Despite the prevalence of higher-level languages, C continues to empower the world. The following are some of the systems that are used by millions and are programmed in the C language.
Microsoft Windows
Microsoft’s Windows kernel is developed mostly in C, with some parts in assembly language. For decades, the world’s most used operating system, with about 90 percent of the market share, has been powered by a kernel written in C.
Linux
Linux is also written mostly in C, with some parts in assembly. About 97 percent of the world’s 500 most powerful supercomputers run the Linux kernel. It is also used in many personal computers.
Mac
Mac computers are also powered by C, since the OS X kernel is written mostly in C. Every program and driver in a Mac, as in Windows and Linux computers, is running on a C-powered kernel.
Mobile
iOS, Android and Windows Phone kernels are also written in C. They are just mobile adaptations of existing Mac OS, Linux and Windows kernels. So smartphones you use every day are running on a C kernel.
Databases
The world’s most popular databases, including Oracle Database, MySQL, MS SQL Server, and PostgreSQL, are coded in C (the first three of them actually both in C and C++). Databases are used in all kind of systems: financial, government, media, entertainment, telecommunications, health, education, retail, social networks, web, and the like.
3D Movies
3D movies are created with applications that are generally written in C and C++. Those applications need to be very efficient and fast, since they handle a huge amount of data and do many calculations per second. The more efficient they are, the less time it takes for the artists and animators to generate the movie shots, and the more money the company saves.
Embedded Systems
Imagine that you wake up one day and go shopping. The alarm clock that wakes you up is likely programmed in C. Then you use your microwave or coffee maker to make your breakfast. They are also embedded systems and therefore are probably programmed in C. You turn on your TV or radio while you eat your breakfast. Those are also embedded systems, powered by C. When you open your garage door with the remote control you are also using an embedded system that is most likely programmed in C.
Then you get into your car. If it has the following features, also programmed in C:
- automatic transmission
- tire pressure detection systems
- sensors (oxygen, temperature, oil level, etc.)
- memory for seats and mirror settings.
- dashboard display
- anti-lock brakes
- automatic stability control
- cruise control
- climate control
- child-proof locks
- keyless entry
- heated seats
- airbag control
You get to the store, park your car and go to a vending machine to get a soda. What language did they use to program this vending machine? Probably C. Then you buy something at the store. The cash register is also programmed in C. And when you pay with your credit card? You guessed it: the credit card reader is, again, likely programmed in C.
All those devices are embedded systems. They are like small computers that have a microcontroller/microprocessor inside that is running a program, also called firmware, on embedded devices. That program must detect key presses and act accordingly, and also display information to the user. For example, the alarm clock must interact with the user, detecting what button the user is pressing and, sometimes, how long it is being pressed, and program the device accordingly, all while displaying to the user the relevant information. The anti-lock brake system of the car, for example, must be able to detect sudden locking of the tires and act to release the pressure on the brakes for a small period of time, unlocking them, and thereby preventing uncontrolled skidding. All those calculations are done by a programmed embedded system.
Although the programming language used on embedded systems can vary from brand to brand, they are most commonly programmed in the C language, due to the language’s features of flexibility, efficiency, performance, and closeness to the hardware.
Why is the C Programming Language Still Used?
There are many programming languages, today, that allow developers to be more productive than with C for different kinds of projects. There are higher level languages that provide much larger built-in libraries that simplify working with JSON, XML, UI, web pages, client requests, database connections, media manipulation, and so on.
But despite that, there are plenty of reasons to believe that C programming will remain active for a long time. In programming languages one size does not fit all. Here are some reasons that C is unbeatable, and almost mandatory, for certain applications.
Portability and Efficiency
C is almost a portable assembly language. It is as close to the machine as possible while it is almost universally available for existing processor architectures. There is at least one C compiler for almost every existent architecture. And nowadays, because of highly optimized binaries generated by modern compilers, it’s not an easy task to improve on their output with hand written assembly.
Such is its portability and efficiency that “compilers, libraries, and interpreters of other programming languages are often implemented in C”. Interpreted languages like Python, Ruby, and PHP have their primary implementations written in C. It is even used by compilers for other languages to communicate with the machine. For example, C is the intermediate language underlying Eiffel and Forth. This means that, instead of generating machine code for every architecture to be supported, compilers for those languages just generate intermediate C code, and the C compiler handles the machine code generation.
C has also become a lingua franca for communicating between developers. As Alex Allain, Dropbox Engineering Manager and creator of Cprogramming.com, puts it:
“C is a great language for expressing common ideas in programming in a way that most people are comfortable with. Moreover, a lot of the principles used in C – for instance, argc and argv for command line parameters, as well as loop constructs and variable types – will show up in a lot of other languages you learn so you’ll be able to talk to people even if they don’t know C in a way that’s common to both of you.”
Memory Manipulation
Arbitrary memory address access and pointer arithmetic is an important feature that makes C a perfect fit for system programming (operating systems and embedded systems).
At the hardware/software boundary, computer systems and microcontrollers map their peripherals and I/O pins into memory addresses. System applications must read and write to those custom memory locations to communicate with the world. So C’s ability to manipulate arbitrary memory addresses is imperative for system programming.
A microcontroller could be architected, for example, such that the byte in memory address 0x40008000 will be sent by the universal asynchronous receiver/transmitter (or UART, a common hardware component for communicating with peripherals) every time bit number 4 of address 0x40008001 is set to 1, and that after you set that bit, it will be automatically unset by the peripheral.
This would be the code for a C function that sends a byte through that UART:
#define UART_BYTE *(char *)0x40008000
#define UART_SEND *(volatile char *)0x40008001 |= 0x08
void send_uart(char byte)
{
UART_BYTE = byte; // write byte to 0x40008000 address
UART_SEND; // set bit number 4 of address 0x40008001
}
The first line of the function will be expanded to:
*(char *)0x40008000 = byte;
This line tells the compiler to interpret the value 0x40008000 as a pointer to a char, then to dereference (give the value pointed to by) that pointer (with the leftmost * operator) and finally to assign byte value to that dereferenced pointer. In other words: write the value of variable byte to memory address 0x40008000.
The next line will be expanded to:
*(volatile char *)0x40008001 |= 0x08;
In this line, we perform a bitwise OR operation on the value at address 0x40008001 and the value 0x08 (00001000 in binary, i.e., a 1 in bit number 4), and save the result back to address 0x40008001. In other words: we set bit 4 of the byte that is at address 0x40008001. We also declare that the value at address 0x40008001 is volatile. This tells the compiler that this value may be modified by processes external to our code, so the compiler won’t make any assumptions about the value in that address after writing to it. (In this case, this bit is unset by the UART hardware just after we set it by software.) This information is important for the compiler’s optimizer. If we did this inside a for loop, for example, without specifying that the value is volatile, the compiler might assume this value never changes after being set, and skip executing the command after the first loop.
Deterministic Usage of Resources
A common language feature that system programming cannot rely on is garbage collection, or even just dynamic allocation for some embedded systems. Embedded applications are very limited in time and memory resources. They are often used for real-time systems, where a non-deterministic call to the garbage collector cannot be afforded. And if dynamic allocation cannot be used because of the lack of memory, it is very important to have other mechanisms of memory management, like placing data in custom addresses, as C pointers allow. Languages that depend heavily on dynamic allocation and garbage collection wouldn’t be a fit for resource-limited systems.
Code Size
C has a very small runtime. And the memory footprint for its code is smaller than for most other languages.
When compared to C++, for example, a C-generated binary that goes to an embedded device is about half the size of a binary generated by similar C++ code. One of the main causes for that is exceptions support.
Exceptions are a great tool added by C++ over C, and, if not triggered and smartly implemented, they have practically no execution time overhead (but at the cost of increasing the code size).
Let’s see an example in C++:
// Class A declaration. Methods defined somewhere else;
class A
{
public:
A(); // Constructor
~A(); // Destructor (called when the object goes out of scope or is deleted)
void myMethod(); // Just a method
};
// Class B declaration. Methods defined somewhere else;
class B
{
public:
B(); // Constructor
~B(); // Destructor
void myMethod(); // Just a method
};
// Class C declaration. Methods defined somewhere else;
class C
{
public:
C(); // Constructor
~C(); // Destructor
void myMethod(); // Just a method
};
void myFunction()
{
A a; // Constructor a.A() called. (Checkpoint 1)
{
B b; // Constructor b.B() called. (Checkpoint 2)
b.myMethod(); // (Checkpoint 3)
} // b.~B() destructor called. (Checkpoint 4)
{
C c; // Constructor c.C() called. (Checkpoint 5)
c.myMethod(); // (Checkpoint 6)
} // c.~C() destructor called. (Checkpoint 7)
a.myMethod(); // (Checkpoint 8)
} // a.~A() destructor called. (Checkpoint 9)
Methods of A, B and C classes are defined somewhere else (for example in other files). Therefore the compiler cannot analyze them and cannot know if they will throw exceptions. So it must prepare to handle exceptions thrown from any of their constructors, destructors, or other method calls. Destructors should not throw (very bad practice), but the user could throw anyway, or they could throw indirectly by calling some function or method (explicitly or implicitly) that throws an exception.
If any of the calls in myFunction throw an exception, the stack unwinding mechanism must be able to call all the destructors for the objects that were already constructed. One implementation for the stack unwinding mechanism will use the return address of the last call from this function to verify the “checkpoint number” of the call that triggered the exception (this is the simple explanation). It does this by making use of an auxiliary autogenerated function (a kind of look-up table) that will be used for stack unwinding in case an exception is thrown from the body of that function, which will be similar to this:
// Possible autogenerated function
void autogeneratedStackUnwindingFor_myFunction(int checkpoint)
{
switch (checkpoint)
{
// case 1 and 9: do nothing;
case 3: b.~B(); goto destroyA; // jumps to location of destroyA label
case 6: c.~C(); // also goes to destroyA as that is the next line
destroyA: // label
case 2: case 4: case 5: case 7: case 8: a.~A();
}
}
If the exception is thrown from checkpoints 1 and 9, no object needs destruction. For checkpoint 3, b and a must be destructed. For checkpoint 6, c and a must be destructed. In all cases the destruction order must be respected. For checkpoints 2, 4, 5, 7, and 8, only object a needs to be destructed.
This auxiliary function adds size to the code. This is part of the space overhead that C++ adds to C. Many embedded applications cannot afford this extra space. Therefore, C++ compilers for embedded systems often have a flag to disable exceptions. Disabling exceptions in C++ is not free, because the Standard Template Library heavily relies on exceptions to inform errors. Using this modified scheme, without exceptions, requires more training for C++ developers to detect possible issues or find bugs.
And, we are talking about C++, a language whose principle is: “You don’t pay for what you don’t use.” This increase on binary size gets worse for other languages that add additional overhead with other features that are very useful but cannot be afforded by embedded systems. While C does not give you the use of these extra features, it allows a much more compact code footprint than the other languages.
Reasons to Learn C
C is not a hard language to learn, so all the benefits from learning it will come quite cheap. Let’s see some of those benefits.
Lingua Franca
As already mentioned, C is a lingua franca for developers. Many implementations of new algorithms in books or on the internet are first (or only) made available in C by their authors. This gives the maximum possible portability for the implementation. I’ve seen programmers struggling on the internet to rewrite a C algorithm to other programming languages because he or she didn’t know very basic concepts of C.
Be aware that C is an old and widespread language, so you can find all kind of algorithms written in C around the web. Therefore you’ll very likely benefit from knowing this language.
Understand the Machine (Think in C)
When we discuss the behavior of certain portions of code, or certain features of other languages, with colleagues, we end up “talking in C:” Is this portion passing a “pointer” to the object or copying the entire object? Could any “cast” be happening here? And so on.
We would rarely discuss (or think) about the assembly instructions that a portion of code is executing when analyzing the behavior of a portion of code of a high level language. Instead, when discussing what the machine is doing, we speak (or think) pretty clearly in C.
Moreover, if you can’t stop and think that way about what you are doing, you may end up programming with some sort of superstition about how (magically) things are done.
Work on Many Interesting C Projects
Many interesting projects, from big database servers or operating system kernels, to small embedded applications you can even do at home for your personal satisfaction and fun, are done in C. There is no reason to stop doing things you may love for the single reason that you don’t know an old and small, but strong and time-proven programming language like C.
Conclusion
The Illuminati doesn’t run the world. C programmers do.
The C programming language doesn’t seem to have an expiration date. It’s closeness to the hardware, great portability and deterministic usage of resources makes it ideal for low level development for such things as operating system kernels and embedded software. Its versatility, efficiency and good performance makes it an excellent choice for high complexity data manipulation software, like databases or 3D animation. The fact that many programming languages today are better than C for their intended use doesn’t mean that they beat C in all areas. C is still unsurpassed when performance is the priority.
The world is running on C-powered devices. We use these devices every day whether we realize it or not. C is the past, the present, and, as far as we can see, still the future for many areas of software.
“This article was written by Daniel Angel Muñoz Trejo, Argentina , a Toptal developer.”
Top 10 Most Common C++ Mistakes That Developers Make
There are many pitfalls that a C++ developer may encounter. This can make quality programming very hard and maintenance very expensive. Learning the language syntax and having good programming skills in similar languages, like C# and Java, just isn’t enough to utilize C++’s full potential. It requires years of experience and great discipline to avoid errors in C++. In this article, we are going to take a look at some of the common mistakes that are made by developers of all levels if they are not careful enough with C++ development.
Common Mistake #1: Using “new” and ”delete” Pairs Incorrectly
No matter how much we try, it is very difficult to free all dynamically allocated memory. Even if we can do that, it is often not safe from exceptions. Let us look at a simple example:
void SomeMethod()
{
ClassA *a = new ClassA;
SomeOtherMethod(); // it can throw an exception
delete a;
}
If an exception is thrown, the “a” object is never deleted. The following example shows a safer and shorter way to do that. It uses auto_ptr which is deprecated in C++11, but the old standard is still widely used. It can be replaced with C++11 unique_ptr or scoped_ptr from Boost if possible.
void SomeMethod()
{
std::auto_ptr<ClassA> a(new ClassA); // deprecated, please check the text
SomeOtherMethod(); // it can throw an exception
}
No matter what happens, after creating the “a” object it will be deleted as soon as the program execution exits from the scope.
However, this was just the simplest example of this C++ problem. There are many examples when deleting should be done at some other place, perhaps in an outer function or another thread. That is why the use of new/delete in pairs should be completely avoided and appropriate smart pointers should be used instead.
Common Mistake #2: Forgotten Virtual Destructor
This is one of the most common errors that leads to memory leaks inside derived classes if there is dynamic memory allocated inside them. There are some cases when virtual destructor is not desirable, i.e. when a class is not intended for inheritance and its size and performance is crucial. Virtual destructor or any other virtual function introduces additional data inside a class structure, i.e. a pointer to a virtual table which makes the size of any instance of the class bigger.
However, in most cases classes can be inherited even if it is not originally intended. So it is a very good practice to add a virtual destructor when a class is declared. Otherwise, if a class must not contain virtual functions due to performance reasons, it is a good practice to put a comment inside a class declaration file indicating that the class should not be inherited. One of the best options to avoid this issue is to use an IDE that supports virtual destructor creation during a class creation.
One additional point to the subject are classes/templates from the standard library. They are not intended for inheritance and they do not have a virtual destructor. If, for example, we create a new enhanced string class that publicly inherits from std::string there is possibility that somebody will use it incorrectly with a pointer or a reference to std::string and cause a memory leak.
class MyString : public std::string
{
~MyString() {
// …
}
};
int main()
{
std::string *s = new MyString();
delete s; // May not invoke the destructor defined in MyString
}
To avoid such C++ issues, a safer way of reusing of a class/template from the standard library is to use private inheritance or composition.
Common Mistake #3: Deleting an Array With “delete” or Using a Smart Pointer
Creating temporary arrays of dynamic size is often necessary. After they are not required anymore, it is important to free the allocated memory. The big problem here is that C++ requires special delete operator with [] brackets, which is forgotten very easily. The delete[] operator will not just delete the memory allocated for an array, but it will first call destructors of all objects from an array. It is also incorrect to use the delete operator without [] brackets for primitive types, even though there is no destructor for these types. There is no guarantee for every compiler that a pointer to an array will point to the first element of the array, so using delete without [] brackets can result in undefined behaviour too.
Using smart pointers, such as auto_ptr, unique_ptr<T>, shared_ptr, with arrays is also incorrect. When such a smart pointer exits from a scope, it will call a delete operator without [] brackets which results in the same issues described above. If using of a smart pointer is required for an array, it is possible to use scoped_array or shared_array from Boost or a unique_ptr<T[]> specialization.
If functionality of reference counting is not required, which is mostly the case for arrays, the most elegant way is to use STL vectors instead. They don’t just take care of releasing memory, but offer additional functionalities as well.
Common Mistake #4: Returning a Local Object by Reference
This is mostly a beginner’s mistake, but it is worth mentioning since there is a lot of legacy code that suffers from this issue. Let’s look at the following code where a programmer wanted to do some kind of optimization by avoiding unnecessary copying:
Complex& SumComplex(const Complex& a, const Complex& b)
{
Complex result;
…..
return result;
}
Complex& sum = SumComplex(a, b);
The object “sum” will now point to the local object “result”. But where is the object “result” located after the SumComplex function is executed? Nowhere. It was located on the stack, but after the function returned the stack was unwrapped and all local objects from the function were destructed. This will eventually result in an undefined behaviour, even for primitive types. To avoid performance issues, sometimes it is possible to use return value optimization:
Complex SumComplex(const Complex& a, const Complex& b)
{
return Complex(a.real + b.real, a.imaginar + b.imaginar);
}
Complex sum = SumComplex(a, b);
For most of today’s compilers, if a return line contains a constructor of an object the code will be optimized to avoid all unnecessary copying – the constructor will be executed directly on the “sum” object.
Common Mistake #5: Using a Reference to a Deleted Resource
These C++ problems happen more often than you may think, and are usually seen in multithreaded applications. Let us consider the following code:
Thread 1:
Connection& connection= connections.GetConnection(connectionId);
// …
Thread 2:
connections.DeleteConnection(connectionId);
// …
Thread 1:
connection.send(data);
In this example, if both threads used the same connection ID this will result in undefined behavior. Access violation errors are often very hard to find.
In these cases, when more than one thread accesses the same resource it is very risky to keep pointers or references to the resources, because some other thread can delete it. It is much safer to use smart pointers with reference counting, for example shared_ptr from Boost. It uses atomic operations for increasing/decreasing a reference counter, so it is thread safe.
Common Mistake #6: Allowing Exceptions to Leave Destructors
It is not frequently necessary to throw an exception from a destructor. Even then, there is a better way to do that. However, exceptions are mostly not thrown from destructors explicitly. It can happen that a simple command to log a destruction of an object causes an exception throwing. Let’s consider following code:
class A
{
public:
A(){}
~A()
{
writeToLog(); // could cause an exception to be thrown
}
};
// …
try
{
A a1;
A a2;
}
catch (std::exception& e)
{
std::cout << “exception caught”;
}
In the code above, if exception occurs twice, such as during the destruction of both objects, the catch statement is never executed. Because there are two exceptions in parallel, no matter whether they are of the same type or different typ
e the C++ runtime environment does not know how to handle it and calls a terminate function which results in termination of a program’s execution.
So the general rule is: never allow exceptions to leave destructors. Even if it is ugly, potential exception has to be protected like this:
try
{
writeToLog(); // could cause an exception to be thrown
}
catch (…) {}
Common Mistake #7: Using “auto_ptr” (Incorrectly)
The auto_ptr template is deprecated from C++11 because of a number of reasons. It is still widely used, since most projects are still being developed in C++98. It has a certain characteristic that is probably not familiar to all C++ developers, and could cause serious problems for somebody who is not careful. Copying of auto_ptr object will transfer an ownership from one object to another. For example, the following code:
auto_ptr<ClassA> a(new ClassA); // deprecated, please check the text
auto_ptr<ClassA> b = a;
a->SomeMethod(); // will result in access violation error
… will result in an access violation error. Only object “b” will contain a pointer to the object of Class A, while “a” will be empty. Trying to access a class member of the object “a” will result in an access violation error. There are many ways of using auto_ptr incorrectly. Four very critical things to remember about them are:
- Never use auto_ptr inside STL containers. Copying of containers will leave source containers with invalid data. Some STL algorithms can also lead to invalidation of “auto_ptr”s.
- Never use auto_ptr as a function argument since this will lead to copying, and leave the value passed to the argument invalid after the function call.
- If auto_ptr is used for data members of a class, be sure to make a proper copy inside a copy constructor and an assignment operator, or disallow these operations by making them private.
- Whenever possible use some other modern smart pointer instead of auto_ptr.
Common Mistake #8: Using Invalidated Iterators and References
It would be possible to write an entire book on this subject. Every STL container has some specific conditions in which it invalidates iterators and references. It is important to be aware of these details while using any operation. Just like the previous C++ problem, this one can also occur very frequently in multithreaded environments, so it is required to use synchronization mechanisms to avoid it. Lets see the following sequential code as an example:
vector<string> v;
v.push_back(“string1”);
string& s1 = v[0]; // assign a reference to the 1st element
vector<string>::iterator iter = v.begin(); // assign an iterator to the 1st element
v.push_back(“string2”);
cout << s1; // access to a reference of the 1st element
cout << *iter; // access to an iterator of the 1st element
From a logical point of view the code seems completely fine. However, adding the second element to the vector may result in reallocation of the vector’s memory which will make both the iterator and the reference invalid and result in an access violation error when trying to access them in the last 2 lines.
Common Mistake #9: Passing an Object by Value
You probably know that it is a bad idea to pass objects by value due to its performance impact. Many leave it like that to avoid typing extra characters, or probably think of returning later to do the optimization. It usually never gets done, and as a result leads to lesser performant code and code that is prone to unexpected behavior:
class A
{
public:
virtual std::string GetName() const {return “A”;}
…
};
class B: public A
{
public:
virtual std::string GetName() const {return “B”;}
…
};
void func1(A a)
{
std::string name = a.GetName();
…
}
B b;
func1(b);
This code will compile. Calling of the “func1” function will create a partial copy of the object “b”, i.e. it will copy only class “A”’s part of the object “b” to the object “a” (“slicing problem”). So inside the function it will also call a method from the class “A” instead of a method from the class “B” which is most likely not what is expected by somebody who calls the function.
Similar problems occur when attempting to catch exceptions. For example:
class ExceptionA: public std::exception;
class ExceptionB: public ExceptionA;
try
{
func2(); // can throw an ExceptionB exception
}
catch (ExceptionA ex)
{
writeToLog(ex.GetDescription());
throw;
}
When an exception of type ExceptionB is thrown from the function “func2” it will be caught by the catch block, but because of the slicing problem only a part from the ExceptionA class will be copied, incorrect method will be called and also re-throwing will throw an incorrect exception to an outside try-catch block.
To summarize, always pass objects by reference, not by value.
Common Mistake #10: Using User Defined Conversions by Constructor and Conversion Operators
Even the user defined conversions are very useful sometimes, but they can lead to unpredicted conversions that are very hard to locate. Let’s say somebody created a library that has a string class:
class String
{
public:
String(int n);
String(const char *s);
….
}
The first method is intended to create a string of a length n, and the second is intended to create a string containing the given characters. But the problem starts as soon as you have something like this:
String s1 = 123;
String s2 = ‘abc’;
In the example above, s1 will become a string of size 123, not a string that contains the characters “123”. The second example contains single quotation marks instead of double quotes (which may happen by accident) which will also result in calling of the first constructor and creating a string with a very big size. These are really simple examples, and there are many more complicated cases that lead to confusion and unpredicted conversions that are very hard to find. There are 2 general rules of how to avoid such problems:
- Define a constructor with explicit keyword to disallow implicit conversions.
- Instead of using conversion operators, use explicit conversation methods. It requires a little bit more typing, but it is much cleaner to read and can help avoid unpredictable results.
Conclusion
C++ is a powerful language. In fact, many of the applications that you use every day on your computer and have come to love are probably built using C++. As a language, C++ gives a tremendous amount of flexibility to the developer, through some of the most sophisticated features seen in object-oriented programming languages. However, these sophisticated features or flexibilities can often become the cause of confusion and frustration for many developers if not used responsibly. Hopefully this list will help you understand how some of these common mistakes influence what you can achieve with C++.
“This article was written by Vatroslav Bodrozic , a Toptal developer.”
How to Get Maximum Square Area in a Rectangle using Dynamic Programming? | Computing & Technology
How to Get Maximum Square Area in a Rectangle using Dynamic Programming? There is a 2D binary matrix M filled with 0’s and 1’s, your task is to find the largest square containing all 1’s and return its area. For example,
Source: How to Get Maximum Square Area in a Rectangle using Dynamic Programming? | Computing & Technology
Best Programming Editors? A Never Ending Battle With No Clear Winner
Regardless of the apparent evidence to the contrary, programmers are humans. And, as all humans, we like taking advantage over our freedom of choice. Whether that choice is about taking the red pill or the blue pill, wearing a dress or pants, or using one development environment over another, the choice we make places us in one group of people or another. Choice, inevitably, comes after our evaluation of options. And having made a choice, we tend to believe that anyone who chooses differently made a mistake.
You can easily search the internet and find hundreds of debates about Emacs vs Vim. Even if you read them all, it will be impossible to objectively choose a winner. However, does the choice of development environment tell you anything about the quality of work a developer can deliver? Absolutely not!
A great developer could write her code into Notepad and still deliver great stuff.
Certainly, there are a lot of things professionals consider when selecting tools for their work. This is true for every profession, including software development. Quite often, however, selection is based on personal taste, not something easily tangible.
Programmers spend most of their time looking at the development environment, so it is natural that we want something pretty as well as functional. Every development environment has its pros and cons. As a whole, they a driving force of the software development industry.
What are the things a developer should evaluate when choosing a set of programming tools like a programming editor of choice? The answer to this question is not as simple as it might sound. Software development is close to an art, and there are quite few “fuzzy” factors that separate a masterpiece from an overpriced collectable.
Every programming language, be it Java, C#, PHP, Python, Ruby, JavaScript, and so on, has its own development practices related to project structure, debugging, and deploying. However, one thing they all have in common is editing code. In this article we will evaluate different development platforms from the perspective of the most common task in software development: writing code.
IDE vs General Purpose Text Editor
An integrated development environment (IDE) (or interactive development environment) is a software application that provides comprehensive facilities to computer programmers for software development. An IDE normally consists of a source code editor, build automation tools, and a debugger, and many support lots of additional plugins and extensions.
Text editors are simpler applications. Compared to IDEs, they usually correspond to just the code editor segment of an IDE. However, they are often much more than that. IDEs are created to serve the purpose of software development, while many text editors are designed to be used by non-developers as well.
Static-typed languages can get a lot of benefits from IDEs. Because of the strict typing rules, it is possible for the IDE to detect bugs and naming inconsistencies across classes and modules, and even across files, directly in the editor, before compiling. This functionality comes standard with many IDEs, and for that reason, IDEs are very popular for static-typed languages.
However, it is impossible to do the same thing for dynamically typed languages. For example, if a method name may be generated by the code itself, constructed from a series of string concats, trying to detect naming errors in dynamic languages requires nothing less than running the actual program. Because one of the major benefits of IDEs does not apply to dynamic language programmers, they have a greater tendency to stick with text editors like Sublime. As a side note, this is also a major reason why the test-driven development movement has grown up around dynamic language communities, and has not had as strong of a following in static languages.
What Makes a Great Programming Editor?
Aside from a number of different features for various languages, every programming editor needs to have a well-organized and clean user interface. Overall aesthetic appeal should not be overlooked, either. It is not just a matter of looking good, as a well-designed editor with the right choice of font and colors helps keep eyestrain down and lets you be more productive.
In today’s development environment, a steep learning curve is a liability, regardless of feature set. Time is always valuable, so a good editor should be easy to get used to. Ideally, the programmer should be able to start work immediately, without having to jump through too many hoops. A Swiss army knife is a practical and useful tool, yet anyone can master it in minutes. Likewise, for programming editors, simplicity is a virtue.
User Interface, Features, and Workflow
Let’s take a closer look at UI, different features and capabilities, and frequently used tools that should be a part of any programming editor.
Line numbers, of course, should be on by default and simple to turn on or off.
Snippets are useful for inserting standardized blocks of text in a fixed layout. However, programming is a lot about saying things just once, so be careful with snippets as they might make your code hard to maintain in the future.
The ability to lint, or syntax-check, the current file is useful, as is the ability to launch it. Without this facility, a programmer must switch to an external command line window, choose and run the correct command, and then step through error messages to find the source of the error. However, the linting must be under the programmer’s control, because the delay incurred by the lint might interrupt the coder at a crucial moment.
Inline doc is useful as long as it does not get in the way, but having a browser page open on the class definitions is sometimes more useful, especially when there are lots of related classes that do not directly extend each other. It is easy enough to cut and paste code from the browser documentation to the code being written, so the additional complexity of inline documentation often becomes less useful, indeed, more annoying, as the programmer’s knowledge of the documentation increases.
Word-completion is helpful since it is fast, and almost as reliable as in-edit documentation, while being less intrusive. It is satisfying to enter just a few characters of a word and then hit enter to get the rest. Otherwise, one labors under the strain of excess typing, abhorred by lazy programmers, who want to type ee rather than the more lengthy exponentialFunctionSquared. Word completion satisfies by minimizing typing, enforcing coherent naming and by not getting in the way.
Renaming variables and functions across the program is useful, but you need to be able to review changes and make sure your code is not broken. Again, word completion is a useful halfway house, in that it works for all languages; you can use long names for items that have long lifetimes, without incurring a typing overhead. You can use references to them via a shorter name locally, in order to shorten expressions which might otherwise spread over too many lines. If you need to rename, the long names are unique, so this approach works across all languages, and all files.
Source files can sometimes grow a lot. Code-folding is a nice feature that simplifies reading through long files.
Find/change with scope limitation to local, incremental, or global with meta characters and regular expressions are part of the minimum requirement these days, as is syntax highlighting.
Overview of Popular Programming Editors
Over the years, I went through a number of editors, and this is what I think of them:
- Emacs: One of the most popular editors in the world. Emacs’ greatest feature is its extensibility, despite the complexity of its extension language (you can even play Tetris in it with M-x tetris). Emacs fans consider its terminal-based interface to be a great feature, while others might debate that it’s a drawback. In my personal experience, I found it too much to adopt and learn. I am sure that if you know how to use Emacs you will never use anything else, but to take on and learn the entire culture was more than I wanted to do. Nevertheless, its popularity among developers proves that it is far from being a relic of the old times, and remains part of our future as well.
- Vi/Vim: Vim is another powerful terminal-based editor, and it comes standard with most xNIX operating systems. Apart from having a different interface than Emacs, my view is practically the same. If you grew up on it, I am sure you will never use anything else. Having Vi skills will make your life much simpler when operating through SSH and other tight spots, and you wont have problems with speed, once you get familiar with keystrokes. While not as tough to crack into as Emacs, the learning curve is still quite steep, and it could definitely use few nice features of a windowed editor.
- SublimeText: True to its name, SublimeText is a beautiful text editor with tons of features. Unlike some similar editors, SublimeText is closed source, so it cannot be modified at a low level. SublimeText offers the simplicity of traditional text editors, with a lean and fast UI. Many developers find it easier to use than Vim, and this is especially true of newcomers. The learning curve just isn’t as steep. While the UI is minimal and straightforward, SublimeText does offer a few nifty features, such as a scaled down display code on the right of the UI, allowing users to quickly scroll through their code and navigate with relative ease. While it’s not completely free, the feature-limited demo version is. Unlocking all the features will cost you $70.
- Atom is the result of a GitHub effort to produce a programming editor for a new generation of developers. While it is still a work in progress, Atom is a very capable editor with a vibrant community of developers keen on new extensions, JavaScript libraries and more. It’s downsides include some UI quirks, the possibility that some add-on packages could misbehave, and reported performance issues when working with (very) big files. But the project is under active development, and current shortcomings are likely to be improved. Atom is an open source project, and it can easily be hacked to suit your needs.
- Nano: Excellent in a tight corner, but not feature-rich enough to prevent the inevitable thought creeping into one’s mind that there must be faster way to do this as one struggles through the keystrokes to indent a block of code, while keeping the comments lined up in column 80! It does not even have text highlighting, and should not be used for anything more than config file changes.
- TextMate2: TextMate’s biggest drawback is that it only runs on Mac. As its creators put it, “TextMate brings Apple’s approach to operating systems into the world of text editors.” By bridging UNIX underpinnings and GUI, TextMate cherry-picks the best of both worlds, to the benefit of expert scripters and novice users alike. It is the editor of choice for many Ruby, Python, and JavaScript developers, with great support for Bash or Markdown as well. At the moment of publishing this article TextMate 2 is still in Beta, but it already has a very mature plugin ecosystem that promises to extend it even beyond Emacs’s extensions.
- jEdit: Java-based, and considered slow by some. Out of the box configuration might push certain people away, but jEdit can be extremely fast if configured properly, as well as extremely nice looking.
- Eclipse: Another widely used IDE, Eclipse is very popular among Java developers, but has been adapted to many different platforms. We could argue that its monolithic architecture is a rock that will pull it under the water, but it is still one of the most popular platforms among developers.
- Aptana Studio: A comprehensive open-source web application IDE. It is available as an Eclipse plugin, which makes it popular among some Java developers. The standalone version is even leaner, and offers a range of different themes and customization options. Aptana’s project management capabilities may also come in handy to coders who honed their skills in Eclipse. While earlier versions suffered from performance issues on some hardware platforms, these problems were addressed in Aptana Studio 3, and should be a thing of the past.
- NetBeans: Another relatively popular open-source IDE with cross-platform support. It is somewhat slower on startup than lean editors like SublimeText, and the choice of add-ons is limited compared to some alternatives. Many Java developers have grown to love NetBeans thanks to seamless SCM integration and HTML5 support. NetBeans support for PHP has also improved in the latest releases.
- JetBrains: Offers a family of IDEs for Java, Ruby, Python and PHP. They are all based on the same core engine. Very capable in its own right, JetBrains IDEs have been gaining a growing following. However, they are not free, open-source solutions, although a 30-day trial is available, and pricing is reasonable.
- Komodo Edit: Komodo Edit has great potential, and yet it’s full of annoying little “gotchas” and idiosyncrasies that can be frustrating by its lack of orthogonality. Komodo Edit feels cluttered, which is a shame because it clearly has immense capability. I keep going back to Komodo Edit in the hopes that I have missed some organizing principle, and every time, I am beaten back by a welter of disorganized capability.
- Geany: Geany is not a major power player like many of the other editors in this list. It is defined more by “what it is not” than “what it is.” It is not slow, it does not have a lot of heritage from the old days, it does not have a macro capability, or much of a multi window on buffer capability. Yet the things it does do, it does well enough. It is, perhaps, the least demanding of all the editors that I tried and still can do 90 percent of what you would expect from a programmer’s editor. Geany looks good enough on Ubuntu, which is one of the reason I chose it as my preferred editor.
My Conclusion
It would be presumptuous to declare just one as the best programming editor among these great tools. And there are quite a few editors I did not even try. There is no one-size-fits-all solution. This is what compelled me to try out a number of different editors.
I currently am using Geany, but it’s because it fits the requirements I have. With Geany, and a lot of help from Perl/Gimp/Audacity/Sox, I am able to develop and maintain the Java code-base for the Android apps I develop, prepare them for compilation in different configurations for multiple distributors, source, lint, compile, dex and produce .apk files, and deliver these apps globally.
Your line of development might set a different set of requirements, and I hope I saved you some time in researching for the most appropriate programming editors.
“This article was written by PHILIP R BRENAN, a Toptal Java developer.”
2014 in review
The WordPress.com stats helper monkeys prepared a 2014 annual report for this blog.

Here’s an excerpt:
The concert hall at the Sydney Opera House holds 2,700 people. This blog was viewed about 22,000 times in 2014. If it were a concert at Sydney Opera House, it would take about 8 sold-out performances for that many people to see it.
